
ICNet for Real-Time Semantic Segmentation on High-Resolution Images
Table of Contents

- 주제 소개
- Speed Analysis
- Image Cascade Network Architecture
- ICNet의 특징
- Evaluation (ICNet 성능 결과물)
[ 주제 소개 ]
논문 제목 : ICNet for Real-Time Semantic Segmentation on High-Resolution Images
- Image Cascade Network (ICNet) 은 ECCV 2018에서 발표된 Semantic Segmentation 알고리즘
- Main Idea : segmentation 작업 중 inference 속도를 높이면서도 quality (accuracy)를 희생시키지 않는 것
ICNet은 image cascade network의 약자로 ECCV 2018에서 발표된 Semantic Segmentation 알고리즘입니다. 이 논문의 저자들은 segmentation 작업 중 inference 속도를 높이면서도 quality (즉 accuracy)를 희생시키지 않는 것이 메인 포인트라고 하였습니다.
참고 영상: https://youtu.be/qWl9idsCuLQ
[ Speed Analysis ]
- 크기가 c*h*w인 input image를 k*k*c 크기의 필터 c’개로 convolution하는 과정
- K 또는 V 감소 -> 연산량 감소 -> speed 증가 / accuracy 감소
우선 inference speed를 높이는 것이 목표이므로 속도의 요인을 알아보도록 하겠습니다. V는 Input feature map, K는 Kernel spatial size, 그리고 U는 Output map을 의미합니다. 어떤 이미지가 주어졌을 때, Convolution연산을 수행하는데 필요한 계산은 다음과 같습니다. 즉, 크기가 w,h,c인 input image를 크기가 k,k,c인 필터 c’개로 Convolution 하는 연산의 수는 아래의 보이는 식이 됩니다. 이 때, 연산량을 줄이기 위해서는 커널의 크기 k를 줄이든가 input image의 크기 V를 줄여야 합니다.
오른쪽의 그래프는 PSPNet50에서 이미지의 크기를 줄였을 때의, 계산시간을 비교한 것입니다. 이 때, 두 가지 해상도를 나타내는 그래프 모두 stage 4에 있을 때가 stage 5에서보다 계산량이 1/4만큼 줄어든 것을 확인한 수 있습니다. 이는 stage5에서 convolution layers에 적용되는 커널 개수와 input channel 개수를 2배로 늘렸기 때문입니다. 즉, input image의 크기를 줄이면 계산량이 줄어든다는 것을 알게 되었는데, input image의 크기를 줄이면 detail이 사라지기 때문에 accuracy가 떨어지게 됩니다. 본 논문에서는 계산량을 적게 유지하면서도 accuracy를 높일 수 있는 방법에 대해 논의하고 있습니다.
[ Image Cascade Network Architecture ]
정확도를 높이는 방법은 화면의 구조도에 보이는 multi-branch를 활용하는 것입니다. 즉, 위에서부터 top, medium, bottom branch로 나누어서 진행하는 것입니다.
우선 top branch에서 원본의 1/4크기의 저해상도 이미지를 input으로 사용합니다. Convolution 과정을 통해 이미지 사이즈가 줄어들면서 PSPNet50의 input으로 사용되고, 그렇게 결과적으로 1/32 크기의 feature map을 만듭니다. 이 때, 사이즈가 줄어들면서 segmentation 도중에 디테일을 놓치기도 하지만 필요한 요소들은 얻어낼 수 있습니다. 그렇기 때문에 medium, bottom branch에서는 이미 작업한 것을 바탕으로 안전하게 parameter 개수를 제한하여 놓친 디테일을 복구하는 작업을 하게 됩니다. 이러한 방식으로 prediction 속도는 높이면서 accuracy를 유지하게 됩니다.
ICNet의 구조를 이해하려면 짚고 넘어가야 할 2가지 문제가 있습니다.
제가 Cascade가 담고있는 의미 "폭포처럼 흐르다"에 대해 생각해보았습니다. From the total ICNet architecture picture, we could see that the Image input flows down from top to medium to bottom branch, which clearly reflects the meaning of “cascade” like a waterfall.
Multi-layered neural network를 vision에 적용할 때의 문제점:
위상 배치(topology)를 신경 쓰지 않기 때문에 이미지가 조금이라도 변형(rotation,flip,size changes)되면 새로운 학습데이터로 처리를 해줘야합니다. 따라서 많은 학습 데이터가 필요하고 그만큼 시간도 오래 걸렸습니다.
Ex) 32×32 크기의 이미지를 gray-scale에 적용한다면 256^(32*32) = 256^1024개의 패턴이 나옵니다.
그래서 등장한 것이 CNN입니다. 영상으로부터 특정 feature들을 추출하기 위한 필터를 구현할 때 convolution을 사용합니다. 1개의 필터를 영상 전역에 옮겨가며 반복적으로 적용하여 특징을 추출하고 이와 같은 동작을 여러개의 filter로 반복 수행하므로 아까와 같은 문제점들을 해결할 수 있게 되었습니다.
- Cascade Feature Fusion
이 논문에서는 Cascade Feature Fusion (CFF) unit을 도입하여 각기 다른 해상도의 input 데이터로부터 추출한 cascade 특징들을 결합시켰습니다.
바로 위의 이미지를 보면 F1은 top branch의 feature map, F2는 medium branch의 feature map을 나타냅니다. Feature map의 크기를 맞추기 위해 F1을 upsampling 합니다. 그리고 upsampled feature map을 개선하기 위해 dilated convolution을 적용합니다. F2에 대해서, channel의 수를 F1과 맞추기 위해서 1 by 1 kernel사용해서 projection convolution을 합니다. 그 다음에 과대적합 문제를 방지하기위해 convolution을 적용한 layer에 batch normalization을 사용하고 학습을 최적화 한 후에 element-wise ‘sum’하고 ‘ReLU’ layer를 통과시켜 최종적으로 F2’ feature map을 얻었습니다.
여기서 잠깐! 왜 down sampling이 아니라 dilated convolution을 적용했을까요?
Dilated convolution: 커널 계수가 담긴 픽셀의 사이사이마다 공백을 두고 적용하는 컨볼루션 방법.
- 적은 parameter 개수로 효율적으로 이미지 세그먼테이션 할 수 있음.
- 큰 receptive field에 적은 parameter 개수로 효율적인 segmentation(특징 추출) 가능 ( = 기본 convolution은 주변에 붙어있는 픽셀만 고려하지만 dilated convolution은 receptive field가 커서 멀리에 떨어져있는 픽셀까지 고려함 )
- Detail을 수월하게 잡아냄
예를 들어, 아래의 이미지를 참고하자.
https://towardsdatascience.com/types-of-convolutions-in-deep-learning-717013397f4d
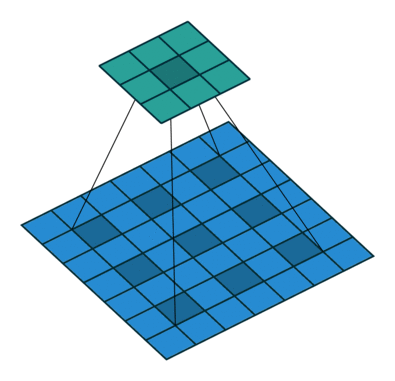
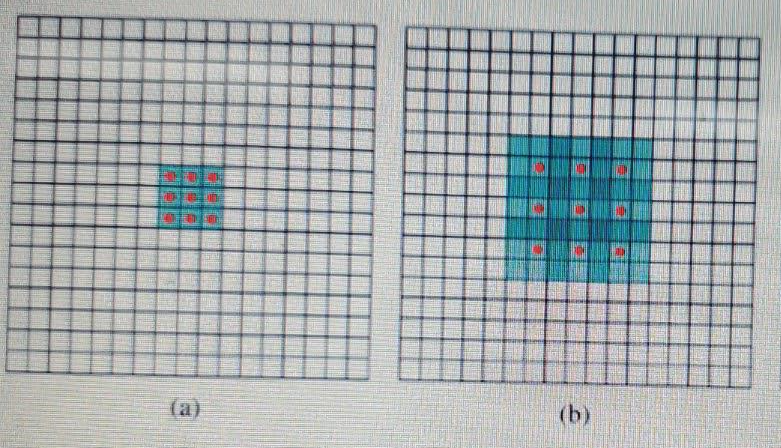
기본 conv는 주변에 붙어있는 픽셀만 고려하지만 dilated conv은 receptive field가 커서 멀리에 떨어져있는 픽셀까지 고려합니다. 이미지 (b)를 보면, receptive field = 7×7 Normal filter로 구현한다면 파라미터 7×7=49개 필요하고, 컨볼루션 과정에서 많은 연산량이 필요합니다.
반면에 dilated convolution을 적용하면 빨간점 9개에만 파라미터가 들어가고 나머지 40개는 0으로 채워지므로 연산량 부담은 3×3 필터를 처리하는 것과 같아집니다! 즉, receptive field는 커지고 파라미터는 적어서 매우 효율적입니다. 따라서 downsampling으로 단순히 처리하는 것보다 dilated conv를 통해 한 번에 더 넓은 영역까지 처리해서 사소한 디테일을 잡아낼 수 있습니다.
- Cascade Label Guidance
“Append weighted softmax cross entropy loss in each branch with related loss weight”
즉, loss를 최종단계에서만 계산하는게 아니라 위의 그림처럼 중간중간에 loss를 구하고, 각 loss에 loss weight (가중치)를 add해서 어느 loss를 더 줄일지 결정합니다.
(예를 들어, loss1(low-res)에 상대적으로 큰 weight 곱하면 loss1을 다른 loss들보다 더 많이 줄여야 전체 loss가 줄어들기 때문에 detail한 부분보다는 전체적인 segmentation 성능을 높일 수 있을 것이고, loss2나 loss3(higher-res)에 큰 weight를 곱하면 detail한 부분을 segmentation 하기 위해 학습을 진행하게 될겁니다.)
또한, 화살표 색상을 보면 top, medium branch로부터 얻은 loss weight (가중치)는 훈련 단계에서만 적용되고, 가장 아래에 있는 고해상도 branch만 test 됨을 알 수 있습니다. 따라서 모든 branch가 골고루 강화되어 최종 결과에 반영됩니다.
[ ICNet 의 특징 ]
그래서 ICNet이 다른 framework와 다른점이 무엇일까요?
우선 구조들만 살펴봤을 때 (a)는 FCN처럼 skip connection을 사용하는 framework, (b)는 SegNet, UNet, ENet 등에서 사용하는 Encoder-decoder structure입니다. (c)는 PSPNet, DeepLab 등에서 사용한 Multi-scale prediction ensemble이 적용된 structure이고, (d)에서는 오직 low-resolution input만 heavy한 CNN에 입력됩니다. Higher-resolution inputs은 blurred boundaries와 missing details를 recover하고 refine하기 위해서 shallow한 신경망의 input으로 사용됩니다.
차이점 :
- 이전 frameworks는 고해상도 데이터를 input으로 주므로 다량의 연산들을 수행해야 합니다. 하지만 ICNet에서는 저해상도 데이터만 가지고 heavy한 컨볼루션을 수행하므로 다른 framework에 비해 연산량이 훨씬 줄어들어서 효율적입니다. Medium, bottom resolution 데이터들은 가벼운 CNN 과정을 거치며 흐려진 부분들과 디테일을 수정해줍니다. (High efficiency SS)
- ICNet은 cascade feature fusion unit과 cascade label guidance strategy를 활용하여 medium& high resolution features를 하나로 통합시키고 semantic map을 점차 개선해나갑니다. (High quality SS)
[ Evaluation (ICNet 성능 결과물) ]
Cityscapes는 high-resolution (1024x2048) image를 다루며, 2975, 500, 1525개의 training, validation and testing sets로 구성된다. 본 논문에서는 road, person, car 등 총 19개의 class에 대하여 train 및 test 하였고 inference speed를 증가시키기 위해 다음과 같이 3가지를 고려했습니다. 첫 번째는 Input image를 down-sampling 하는 것, 두 번째는 Feature map을 down-sampling 하는 것, 세 번째는 model을 compression 하는 것입니다.
1. Down-Sampling Input Image
이 경우에는 input image의 해상도가 중요한 요소입니다. image의 크기를 1/2과 1/4로 down-sampling 해서 PSPNet50에 input으로 주었더니 Inference time이 줄어든 만큼 accuracy도 떨어진 것을 확인할 수 있었습니다.
- Scale= 0.25 -> 작지만 나름 중요한 디테일들을 별로 살려내지 못합니다. (acc 60.7%)
- Scale= 0.50 -> 0.25보다는 낫지만 여전히 신호등 등의 멀리 있는 object를 캐치하지 못하고 경계가 흐릿합니다. (acc 68.4%)
그리고 real-time system이라고 하기엔 processing 할 때 시간이 너무 오래 걸립니다.
2. Down-sampling feature
이번에는 feature에 대한 down-sampling ratio를 1:8, 1:16, 1:32 조절하여 PSPNet50를 테스트 했습니다. Test 결과는 table1의 왼쪽 표와 같습니다. Sample size가 작아질수록 inference 속도는 증가하지만 accuracy가 떨어지는 것을 확인할 수 있습니다.
3. Model Compression
Model compression: 각 layer로부터 filter/커널을 제거하여 복잡하고 무거운 네트워크를 가볍게 만드는 방법
- 각 filter에 대해 커널 l1-norm의 합을 계산하고 내림차순으로 정리하여 가장 의미있는 것들만 갖는 방식으로 진행됩니다.
- Kernel keeping rate가 작을수록 속도는 빨라지지만 accuracy는 상당히 떨어지므로 본 논문에서는 적합하지 못하다고 판단하였습니다.
* Quantitative Investigation
아래의 표는 정량적으로 분석할 결과를 보여줍니다. 가로축인 Bin index는 연결된 region의 크기를 나타내는데, 1은 30 pixel, 2는 60 pixel, 이런식으로 왼쪽은 작은 region, 오른쪽으로 갈수록 큰 region을 의미합니다. 세로축인 accuracy는 각 연결된 region에서 정확하게 prediction한 pixel의 수를 counting해서 연결된 region으로 나눈것을 의미합니다. 즉, 정확히 prediction한 만큼 segmentation accuracy 가 증가했다는 것을 의미합니다. histogram에서 상대적으로 더 작은 region을 나타내는 왼쪽부분에서 accuracy가 높다는 것은 detail한 부분에서 더 많은 개선이 일어났다는 것을 의미합니다.
* Visual Improvement
이전까지는 숫자로 performance improvement 를 나타냈었는데, 다음은 performance improvement를 visually 나타낸 것입니다.
흥미롭게도, table2에서 보았던 sub4이 top branch만을 사용하면서도 대부분의 의미있는 객체를 찝어냈지만 이는 input으로 가장 낮은 해상도를 주었으므로 놓친 특징들이 여전히 발견됩니다. 그리고 이 부분은 sub 24와 sub124를 통해 정확도를 높일 수 있습니다.
그리고, Diff2가 diff1보다 white가 더 얇게 나타나는 것을 보면 좀 더 detail한 inference가 추가되었다는 것을 유추할 수 있습니다.
- diff1(sub4 - sub24)
- diff2(sub24 - sub124)
참고문헌
- https://openaccess.thecvf.com/content_ECCV_2018/papers/Hengshuang_Zhao_ICNet_for_Real-Time_ECCV_2018_paper.pdf
- https://intuitive-robotics.tistory.com/79
- https://blog.naver.com/laonple/220608018546
- https://nanonets.com/blog/semantic-image-segmentation-2020/
- https://blog.naver.com/laonple/220608018546
- https://indoml.com/2018/03/07/student-notes-convolutional-neural-networks-cnn-introduction/
- https://images.app.goo.gl/sfas2R82ZGsdh4h97
- https://towardsdatascience.com/segmentation-and-object-detection-part-1-b8ef6f101547
- https://www.youtube.com/watch?v=qWl9idsCuLQ&feature=youtu.be
'논문_review' 카테고리의 다른 글
| FaceNet : A Unified Embedding for Face Recognition and Clustering (0) | 2020.06.30 |
|---|





