
FaceNet : A Unified Embedding for Face Recognition and Clustering
< Abstract >
FaceNet이라는 시스템을 사용하여 거리를 측정하고 이를 통해 얼굴의 유사도를 유추한다. 여기서 거리란, 닮은 얼굴일수록 거리가 좁혀지고(가깝고) 닮지 않을수록 거리가 멀어진다는 의미이다. 이 시스템에서는 deep convolutional network를 사용하고 학습시킬 때에는 triplets를 사용하여 얼굴 인식 정확도를 99.36%까지 끌어올리는 성과를 내었다.
< Introduction >
이 논문에서는 face verification (같은 사람인지), recognition (이 사람이 누구인지), 그리고 clustering (닮은 얼굴들끼리 묶기)을 위한 통합적 체계를 기준으로 두고, deep convolutional network를 통해 얼굴 이미지를 매핑하여 유클리드 공간에서 얼굴 유사도 (거리)에 대해 살펴본다.
FaceNet은 triplet-based loss function based on LMNN을 통해 결과물이 128-D로 나오도록 조율하는 과정을 거친다. 이 때 사용되는 triplets - 얼굴이 동일하다고 매치되는 두 개의 사진, 매치되지 않는 사진, 그리고 the loss L that aims to separate the positive pair from the negative by a distance margin - 중에서 어느 것을 고를지에 따라 정확도 향상에 큰 영향을 준다.
1. Model Structure and Triplet Loss
핵심 기술 Deep Convolutional Network로 들어가기 전에 알아야 할 두 가지 모델에 대해 얘기해보자.
우선, 아래의 Model Structure을 보면 batch size를 조절하여 "Input Layer"을 형성하는 것으로 시작된다. 그 후에 “Deep Architecture” (Deep CNN) 단계에 들어서고, "L2 Normalization" 과정을 통해 이미지 데이터를 정규화시켜 “Face Embedding”을 이뤄낸다. 마지막에는 모델 훈련시키면서 “Triplet Loss”를 통해 사용자의 얼굴과 닮은 얼굴을 training set에서 검출해낸다 (using previously mentioned triplets).

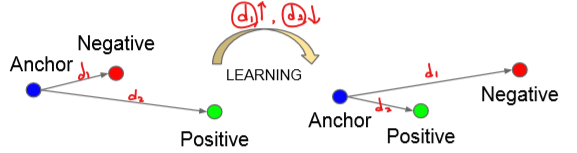
다음으로, Model Structure의 가장 마지막 단계인 Triplet Loss에 대해 살펴보자. 여기서는 anchor과 positive 사이의 거리를 줄이고 anchor 과 negative 사이의 거리를 늘린다. 즉, 더 비슷한 (가까운) identity를 끌어당기면(거리 d2 단축) face verification, recognition, 그리고 clustering 과정 속에서 닮은 얼굴을 검출해낼 수 있다.
Anchor = 특정 인물의 이미지
Positive = anchor 이미지와 닮은 모습의 이미지들
Negative = anchor 이미지와 닮지 않은 모습의 이미지들
2. Triplet Loss
이제 triplet loss의 수학적인 내부 공식을 살펴보도록 하자.
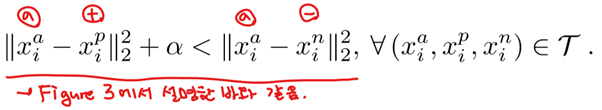
여기서 보면 부등호의 왼쪽이 anchor과 positive 사이의 거리(d2)이고 부등호의 오른쪽이 anchor과 negative 사이의 거리(d1)이다. 알파는 단순히 d2가 d1보다 작아지도록 하는 margin을 뜻하고, T는 training set에 있는 모든 가능한 triplets 집합이고 cardinality N을 가진다. 이 때 f(x)는 d차원 유클리드 공간에서 image(상) x들의 집합이다.
이제 triplet loss L을 수학적으로 계산하면 아래와 같은 공식이 나온다.

이 공식을 보면 가능한 모든 triplet 쌍들을 전부 학습시키면 그만큼 다양한 결과가 나올 것이고 image x는 천천히 수렴하는 모습을 보일 것이다.
3. Different Approaches to use for the triplet selection
우리가 최종적으로 원하는 것은 d(anchor-positive)를 최대한 줄이고 d(anchor-negative)를 최대한 늘이는 것이다. 그러나 mislabel 되었거나 poorly taken image와 같은 경우에서는 우리가 원하는 결과를 얻지 못할 수도 있는데, 이럴 때에는 2가지를 방법을 고려해볼 수 있다.

첫 번째 offline 방법 : inconclusive하므로 이 논문에서는 다루지 않는다.
두 번째 online 방법: 의미있는 결과를 도출해내기 위해서는 한 사람에 대하여 40개의 이미지를 수집하고 하나의 mini-batch에 담는다. 그리고 무작위로 정해진 negative faces가 각 mini-batch에 들어간다. 그 결과, 모든 anchor-positive 쪽이 안정적이고 훈련 시작하는 시점에서 조금 더 빠른 속도로 수렴하는 것을 볼 수 있었다고 한다.
4. Deep Convolutional Network
이 논문에서는 standard backpropagation과 AdaGrad를 활용한 Stochastic Gradient Descent (SGD)로 CNN을 훈련시키는 과정을 보여준다.

< Conclusion >
이번 논문을 읽으며 사람의 얼굴을 측정하는 방법을 발전시키기 위해 사람들이 얼마나 많은 노력을 했는지 알게되었다. 논문에서는 Model structure부터 세우고 triplet loss를 수학적인 공식으로 구현해냈고, FaceNet이 향상된 기능을 선보이도록 triplet loss를 알맞게 설정하는 부분이 개인적으로 가장 놀라웠다. 이미지 속 얼굴의 닮은 정도를 실제로 측정하여 마치 하나의 스펙트럼처럼 [ A와 매우 닮음 -> 매우 닮지 않음(A,B의 혼합) -> B와 매우 닮음 ] 을 보여주는 것 같았다. 또한, batch size, weights 등만 조절할 것이 아니라 convolutional network의 kernel size 조절도 하며 무수히 많은 테스트를 하는 일은 쉽지 않을 것이라고 생각된다.
'논문_review' 카테고리의 다른 글
| ICNet for Real-Time Semantic Segmentation on High-Resolution Images (0) | 2021.01.10 |
|---|





